
AI is set to transform the world for the better, economically and culturally: The past few years have seen a dramatic shift in what AIs can do, the scale at which they are being deployed, and the speed with which these deployments are happening. However, we lack the tools to integrate these technologies to address problems faced by real-world people and organizations.
Our Mission: Our mission is to make scientific contributions in computational methods and human-AI interaction design to augment human capabilities – and in doing so, unlock the potential of what people and organizations can achieve.
Our Strategy: Moving from proofs-of-concept to effective products will require simultaneous innovation in design and machine learning.
Recent CHARM Publications

CorpusStudio: Surfacing Emergent Patterns In A Corpus Of Prior Work While Writing
Hai Dang, Chelse Swoopes, Daniel Buschek, and Elena L. Glassman
CHI ’25, April 26–May 01, 2025, Yokohama, Japan
Many communities, including the scientific community, develop implicit writing norms. Understanding them is crucial for effective communication with that community. Writers gradually develop an implicit understanding of norms by reading papers and receiving feedback on their writing. However, it is difficult to both externalize this knowledge and apply it to one’s own writing. We propose two new writing support concepts that reify document and sentencelevel patterns in a given text corpus: (1) an ordered distribution over section titles and (2) given the user’s draft and cursor location, many retrieved contextually relevant sentences.
“ChatGPT, Don’t Tell Me What to Do”: Designing AI for Context Analysis in Humanitarian Frontline Negotiations
Ma, Zilin; Mei, Yiyang; Bruderlein, Claude; Gajos, Krzysztof Z; Pan, Weiwei
Proceedings of the Symposium on Human-Computer Interaction for Work (CHIWORK), ACM Press, Forthcoming.
Frontline humanitarian negotiators are increasingly exploring ways to use AI tools in their workflows. However, current AI-tools in negotiation primarily focus on outcomes, neglecting crucial aspects of the negotiation process. Through iterative user-centric design with experienced frontline negotiators (n=32), we found that flexible tools that enable contextualizing cases and exploring options (with associated risks) are more effective than those providing direct recommendations of negotiation strategies. Surprisingly, negotiators demonstrated tolerance for occasional hallucinations and biases of AI. Our findings suggest that the design of AI-assisted negotiation tools should build on practitioners’ existing practices, such as weighing different compromises and validating information with peers.
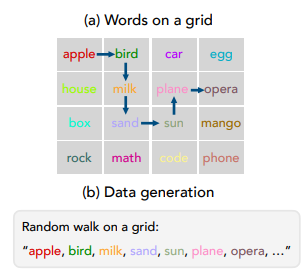
ICLR: In-Context Learning of Representations
Core Francisco Park*, Andrew Lee*, Ekdeep Singh Lubana*, Yongyi Yang*, Maya Okawa, Kento Nishi, Martin Wattenberg, and Hidenori Tanaka
ICLR 2025: International Conference on Learning Representations
Recent work has demonstrated that semantics specified by pretraining data influence how representations of different concepts are organized in a large language model (LLM). However, given the open-ended nature of LLMs, e.g., their ability to in-context learn, we can ask whether models alter these pretraining semantics to adopt alternative, context-specified ones. Specifically, if we provide in-context exemplars wherein a concept plays a different role than what the pretraining data suggests, do models reorganize their representations in accordance with these novel semantics? To answer this question, we take inspiration from the theory of conceptual role semantics and define a toy “graph tracing” task wherein the nodes of the graph are referenced via concepts seen during training (e.g., apple, bird, etc.) and the connectivity of the graph is defined via some predefined structure (e.g., a square grid). Given exemplars that indicate traces of random walks on the graph, we analyze intermediate representations of the model and find that as the amount of context is scaled, there is a sudden re-organization from pretrained semantic representations to in-context representations aligned with the graph structure.
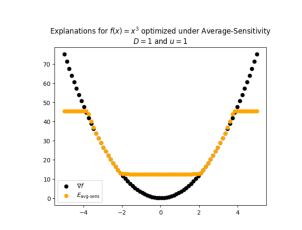
Optimizing Explanations: Nuances Matter When Evaluation Metrics Become Loss Functions
Jonas B Raedler, Hiwot Belay Tadesse, Weiwei Pan, Finale Doshi-Velez
MOSS Workshop @ International Conference on Machine Learning (ICML 2025)
Recent work has introduced a framework that allows users to directly optimize explanations for desired properties and their trade-offs. While powerful in principle, this method repurposes evaluation metrics as loss functions – an approach whose implications are not yet well understood. In this paper, we study how different robustness metrics influence the outcome of explanation optimization, holding faithfulness constant. We do this in the transductive setting, in which all points are available in advance. Contrary to our expectations, we observe that the choice of robustness metric can lead to highly divergent explanations, particularly in higher-dimensional settings. We trace this behavior to the use of metrics that evaluate the explanation set as a whole, rather than imposing constraints on individual points, and to how these “global” metrics interact with other optimization objectives.
If you’re interested in joining our mailing list and hearing about events, newly published papers and upcoming projects, fill out the form below!