Research
Publications
Research from CHARM’s faculty, students, and collaborators across human‑centered AI, interaction design, and machine learning.
2026
-
Bias at the End of the Score
IEEE CVPR 2026
Inverse Transition Learning: Learning Dynamics from Demonstrations
AISTATS 2026
Vidmento: Creating Video Stories through Context-Aware Expansion with Generative Video
CHI 2026
MnemoMaker: Creator, Curator, or Something Else? Exploring Human-AI Mnemonic Co-Creation
CHI 2026 Extended Abstracts (Interactive Demo)
How Notations Evolve: A Historical Analysis with Implications for Supporting User-Defined Abstractions
CHI 2026
A Paradigm for Creative Ownership
CHI 2026
Meta-HCI: Practising Reflection in HCI Research
CHI 2026 Extended Abstracts (Meetup)
Science and Technology for Augmenting Reading (STAR)
CHI 2026 Extended Abstracts (Workshop)

BRIDGE: Borderless Reconfiguration for Inclusive and Diverse Gameplay Experience via Embodiment Transformation
CHI 2026 Best Paper Award
Training resources for parasports are limited, reducing opportunities for athletes and coaches to engage with sport-specific movements and tactical coordination. To address this gap, we developed BRIDGE, a system that integrates a reconstruction pipeline, which detects and tracks players from broadcast video to generate 3D play sequences, with an embodiment-aware visualization framework that decomposes head, trunk, and wheelchair base orientations to represent attention, intent, and mobility. We evaluated BRIDGE in two controlled studies with 20 participants (10 national wheelchair basketball team players and 10 amateur players).The results showed that BRIDGE significantly enhanced the perceived naturalness of player postures and made tactical intentions easier to understand. In addition, it supported functional classification by realistically conveying players’ capabilities, which in turn improved participants’ sense of self-efficacy. This work advances inclusive sports learning and accessible coaching practices, contributing to more equitable access to tactical resources in parasports.
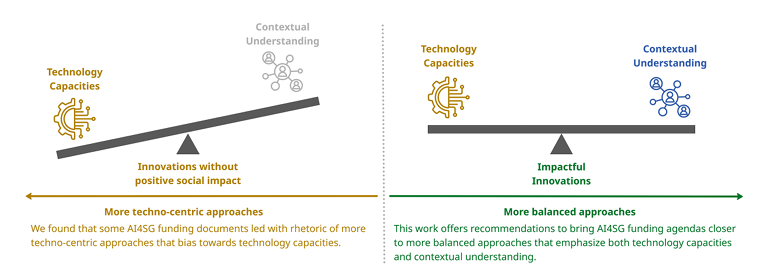
Funding AI for Good: A Call for Meaningful Engagement
CHI 2026
Artificial Intelligence for Social Good (AI4SG) is a growing area that explores AI’s potential to address social issues, such as public health. Yet prior work has shown limited evidence of its tangible benefits for intended communities, and projects frequently face real‑world deployment and sustainability challenges. We conducted a reflexive thematic analysis of 35 funding documents, representing about $410 million USD in total investments.
Beyond Anthropomorphism: a Spectrum of Interface Metaphors for LLMs
CHI 2026
Nonvisual Support for Understanding and Reasoning about Data Structures
CHI 2026
“It just requires so much more creativity”: Barriers and Workarounds to Gathering Information for AI Contestation
CHI 2026
Novel Web-Based Technology to Promote Goal-Setting in Complex Chronic Illness: Randomized Controlled Trial
JMIR Hum Factors, vol. 13, pp. e70402, 2026
ViSTAR: Virtual Skill Training with Augmented Reality with 3D Avatars and LLM coaching agent.
CHI 2026
Federated ADMM from Bayesian Duality
ICLR 2026
Virtual Multiplex Staining for Histological Images Using a Marker-wise Conditioned Diffusion Model
AAAI 2026
2025
-
LangSplatV2: High-dimensional 3D Language Gaussian Splatting with 450+ FPS
NeurIPS 2025
On the Effective Horizon of Inverse Reinforcement Learning
AAMAS 2025
VAIR: Visual Analytics for Injury Risk Exploration in Sports
IEEE VIS 16th Workshop on Visual Analytics in Healthcare (VAHC), 2025.
Tensions of Occupational Identity and Patterns of Identity Protection: Preliminary Insights on Generative AI in the Software Engineering Domain
ICIS 2025 Proceedings
Estimating Upper Extremity Fugl-Meyer Assessment Scores From Reaching Motions Using Wearable Sensors
IEEE 2025
MoMo – Combining Neuron Morphology and Connectivity for Interactive Motif Analysis in Connectomes
IEEE VIS 2025
SynAnno: Interactive Guided Proofreading of Synaptic Annotations
IEEE VIS 2025
Creative Writers’ Attitudes on Writing as Training Data for Large Language Models
CHI 2025 Best Paper Award
The use of creative writing as training data for large language models (LLMs) is highly contentious and many writers have expressed outrage at the use of their work without consent or compensation. In this paper, we seek to understand how creative writers reason about the real or hypothetical use of their writing as training data. We interviewed 33 writers with variation across genre, method of publishing, degree of professionalization, and attitudes toward and engagement with LLMs. We report on core principles that writers express (support of the creative chain, respect for writers and writing, and the human element of creativity) and how these principles can be at odds with their realistic expectations of the world (a lack of control, industry-scale impacts, and interpretation of scale). Collectively these findings demonstrate that writers have a nuanced understanding of LLMs and are more concerned with power imbalances than the technology itself.
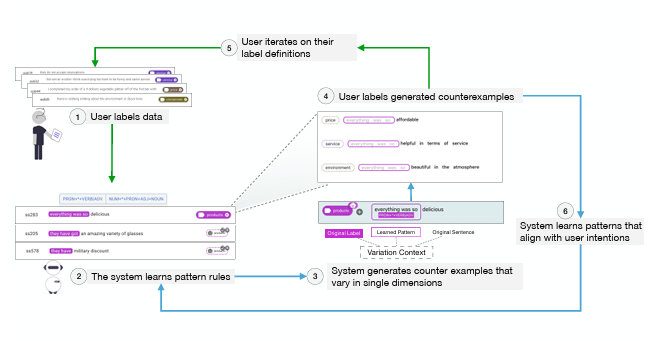
Supporting Co-Adaptive Machine Teaching through Human Concept Learning and Cognitive Theories
CHI 2025 Best Paper Award
An important challenge in interactive machine learning, particularly in subjective or ambiguous domains, is fostering bi-directional alignment between humans and models. Users teach models their concept definition through data labeling, while refining their own understandings throughout the process. To facilitate this, we introduce Mocha, an interactive machine learning tool informed by two theories of human concept learning and cognition. First, it utilizes a neuro-symbolic pipeline to support Variation Theory based counterfactual data generation. By asking users to annotate counterexamples that are syntactically and semantically similar to already-annotated data but predicted to have different labels, the system can learn more effectively while helping users understand the model and reflect on their own label definitions. Second, Mocha uses Structural Alignment Theory to present groups of counterexamples, helping users comprehend alignable differences between data items and annotate them in batch. We validated Mocha’s effectiveness and usability through a lab study with 18 participants.
SEAL: Spatially-resolved Embedding Analysis with Linked Imaging Data
IEEE VIS 2025
niiv: Interactive Self-supervised Neural Implicit Isotropic Volume Reconstruction
MICCAI Workshop on Efficient Medical AI (EMA), 2025
To Recommend or Not to Recommend: Designing and Evaluating AI-Enabled Decision Support for Time-Critical Medical Events
Proc. ACM Hum.-Comput. Interact, vol. 9, iss. CSCW2, 2025.
Transparent Trade-offs between Properties of Explanations
UAI 2025
Frenet-Serret Frame-based Decomposition for Part Segmentation of 3D Curvilinear Structures
IEEE Transactions on Medical Imaging, 2025
The State of Single-Cell Atlas Data Visualization in the Biological Literature
IEEE Computer Graphics and Applications, 2025
Personalising AI assistance based on overreliance rate in AI-assisted decision making
IUI 2025
A connectomic resource for neural cataloguing and circuit dissection of the larval zebrafish brain
bioRxiv, 2025
4D LangSplat: 4D Language Gaussian Splatting via Multimodal Large Language Models
CVPR 2025
Decision-Point Guided Safe Policy Improvement
AISTATS 2025
Toward Accounting for the Effects of Gender Socialization in Quantitative Research in Human-Computer Interaction
Interacting with Computers, 2025.
TriSAM: Tri-Plane SAM for zero-shot cortical blood vessel segmentation in VEM images
IEEE Journal of Biomedical and Health Informatics, 2025
CTRL-GS: Cascaded Temporal Residue Learning for 4D Gaussian Splatting
4D Vision Workshop @ CVPR 2025
AbstractExplorer: Leveraging Structure-Mapping Theory to Enhance Comparative Close Reading at Scale
UIST 2025
Integrated Gradients Provides Faithful Language Model Attributions for In-Context Learning
ICLR 2025 Workshop Building Trust
CAVE: Connectome Annotation Versioning Engine
Nature Methods, 2025
Global Neuron Shape Reasoning with Point Affinity Transformers
bioRxiv, 2025
Semantic Commit: Helping Users Update Intent Specifications for AI Memory at Scale
UIST 2025
Addressing persistent challenges in digital image analysis of cancer tissue: resources developed from a hackathon
Molecular Oncology, 2025
Contrastive Explanations That Anticipate Human Misconceptions Can Improve Human Decision-Making Skills
CHI 2025
SportsBuddy: Designing and Evaluating an AI-Powered Sports Video Storytelling Tool Through Real-World Deployment
IEEE PacificVis 2025
Extending reinforcement Learning-Driven Personalized Health Interventions to Multiple Health Behavioral Change Goals
MOSS Workshop @ ICML 2025
SD-LoRA: Scalable Decoupled Low-Rank Adaptation for Class Incremental Learning
ICLR 2025
Understanding the Relationship between Prompts and Response Uncertainty in Large Language Models
ICLR 2025 Workshop: Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI
Tree of Attributes Prompt Learning for Vision-Language Models
ICLR 2025
Unleashing the Power of Task-Specific Directions in Parameter Efficient Fine-tuning
ICLR 2025
Connecting Federated ADMM to Bayes
ICLR 2025
Connecting Federated ADMM to Bayes
ICLR 2025
Law is vulnerable to AI influence; interface design can help
SSRN Preprint 2025
Bridging Ontologies of Neurological Conditions: Towards Patient-centered Data Practices in Digital Phenotyping Research and Design
Proceedings of the ACM on Human-Computer Interaction, Honorable Mention
Amidst the increasing datafication of healthcare, deep digital phenotyping is being explored in clinical research to gather comprehensive data that can improve understanding of neurological conditions. However, participants currently do not have access to this data due to researchers’ apprehension around whether such data is interpretable or useful. This study focuses on patient perspectives on the potential of deep digital phenotyping data to benefit people with neurodegenerative diseases, such as ataxias, Parkinson’s disease, and multiple system atrophy. We present an interview study (n=12) to understand how people with these conditions currently track their symptoms and how they envision interacting with their deep digital phenotyping data. We describe how participants envision the utility of this deep digital phenotyping data in relation to multiple stages of disease and stakeholders, especially its potential to bridge different and sometimes conflicting understandings of their condition. Looking towards a future in which patients have increased agency over their data and can use it to inform their care, we contribute implications for shaping patient-driven clinical research practices and deep digital phenotyping tools that serve a multiplicity of patient needs.
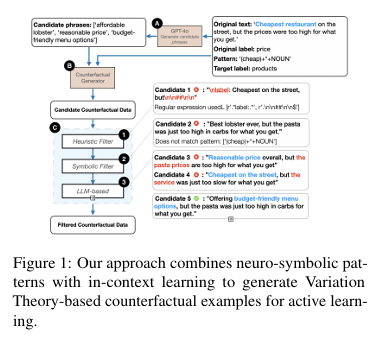
Leveraging Variation Theory in Counterfactual Data Augmentation for Optimized Active Learning
ACL 2025
Active Learning (AL) allows models to learn interactively from user feedback. However, only annotating existing samples may hardly benef it the model’s generalization. Moreover, AL commonly faces a cold start problem due to insufficient annotated data for effective sample selection. To address this, we introduce a counterfactual data augmentation approach inspired by Variation Theory, a theory of human concept learning that emphasizes the essential features of a concept by focusing on what stays the same and what changes. We use a neuro-symbolic pipeline to pinpoint key conceptual dimensions and use a large language model (LLM) to generate targeted variations along those dimensions. Through a text classification experiment, we show that our approach achieves significantly higher performance when there are fewer annotated data, showing its capability to address the cold start problem in AL. We also find that as the annotated training data gets larger, the impact of the generated data starts to diminish. This work demonstrates the value of incorporating human learning theories into the design and optimization of AL.
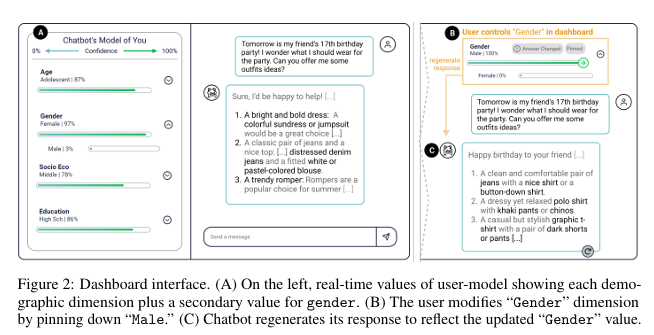
Designing a Dashboard for Transparency and Control of Conversational AI
ICML 2025
Conversational LLMs function as black box systems, leaving users guessing about why they see the output they do. This lack of transparency is potentially problematic, especially given concerns around bias and truthfulness. To address this issue, we present an end-to-end prototype—connecting interpretability techniques with user experience design—that seeks to make chatbots more transparent. We begin by showing evidence that a prominent open-source LLM has a “user model”: examining the internal state of the system, we can extract data related to a user’s age, gender, educational level, and socioeconomic status. Next, we describe the design of a dashboard that accompanies the chatbot interface, displaying this user model in real time. The dashboard can also be used to control the user model and the system’s behavior. Finally, we discuss a study in which users conversed with the instrumented system. Our results suggest that users appreciate seeing internal states, which helped them expose biased behavior and increased their sense of control. Participants also made valuable suggestions that point to future directions for both design and machine learning research. The project page and video demo of our TalkTuner system are available at bit.ly/talktuner-project-page .

Counterfactual Explanations May Not Be the Best Algorithmic Recourse Approach
IUI 2025
Algorithmic recourse is a rapidly developing subfield in explainable AI (XAI) concerned with providing individuals subject to adverse high-stakes algorithmic outcomes with explanations indicating how to reverse said outcomes. While XAI research in the machine learning community doesn’t confine itself to counterfactual explanations, its algorithmic recourse subfield does, adopting the assumption that the optimal way to provide recourse is through counterfactual explanations. Though there has been extensive human-AI interaction research on explanations, translating these findings to the algorithmic recourse setting is non-obvious due to meaningful problem setting differences, leaving the question of whether counterfactuals are the most optimal explanation paradigm for recourse unanswered. While intuitively satisfying, the prescriptive nature of counterfactuals makes them vulnerable to poor outcomes when circumstances unknown to the decision-making and explanation generating algorithms affect re-application strategies. With these concerns in mind, we designed a series of experiments comparing different explanation methods in the recourse setting, explicitly incorporating scenarios where circumstances unknown to the decision-making and explanation algorithms affect re-application strategies. In Experiment 1, we compared counterfactuals with reason codes, a simple feature-based explanation, finding that they both yield comparable re-application success, and that reason codes led to better user outcomes when unknown circumstances had a high impact on re-application strategies. In Experiment 2, we sought to improve on reason code outcomes, comparing them to feature attributions, a more informative feature-based explanation, but found no improvements. Finally, in Experiment 3, we aimed to improve on reason code outcomes with a multiple counterfactual explanation condition, finding that multiple counterfactuals led to higher re-application success but still resulted in comparatively worse user outcomes in the face of high impact unknown circumstances. Taken together, these findings call into question whether the standard counterfactual paradigm is the best approach for the algorithmic recourse problem setting.
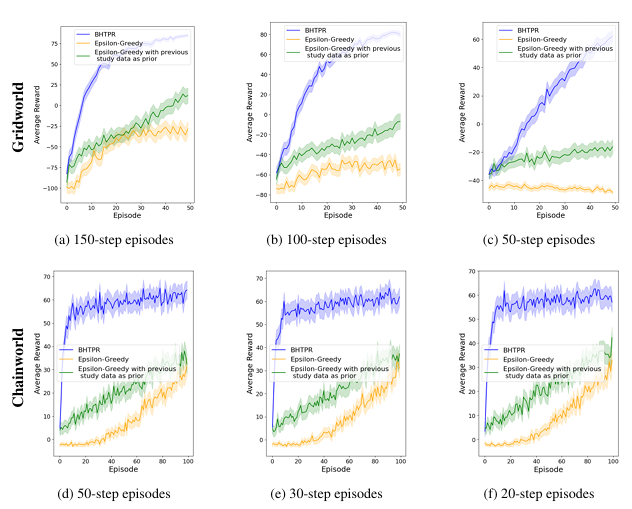
Bayesian Hypothesis Testing Policy Regularization
RLC 2025, ICML 2025
In reinforcement learning (RL), sparse feedback makes it difficult to target long-term outcomes, often resulting in high-variance policies. Real-world interventions instead rely on prior study data, expert input, or short-term proxies to guide exploration. In this work, we propose Bayesian Hypothesis Testing Policy Regularization (BHTPR), a method that integrates a previously-learned policy with a policy learned online to speed up learning in such settings. BHTPR applies the inductive bias that the prior study data matches the current study environment in some states but is incorrect in others. We use Bayesian hypothesis testing to determine, state by state, when to transfer the prior policy and when to rely on online learning.

CorpusStudio: Surfacing Emergent Patterns In A Corpus Of Prior Work While Writing
CHI ’25 · April 26–May 01, 2025 · Yokohama, Japan
Many communities, including the scientific community, develop implicit writing norms. Understanding them is crucial for effective communication with that community. Writers gradually develop an implicit understanding of norms by reading papers and receiving feedback on their writing. However, it is difficult to both externalize this knowledge and apply it to one’s own writing. We propose two new writing support concepts that reify document and sentence‑level patterns in a given text corpus.
“ChatGPT, Don’t Tell Me What to Do”: Designing AI for Context Analysis in Humanitarian Frontline Negotiations
CHIWORK · ACM Press · Forthcoming
Frontline humanitarian negotiators are increasingly exploring ways to use AI tools in their workflows. However, current AI tools in negotiation primarily focus on outcomes, neglecting crucial aspects of the negotiation process. Through iterative user‑centric design with experienced frontline negotiators (n=32), we found that flexible tools that enable contextualizing cases and exploring options are more effective than those providing direct recommendations.
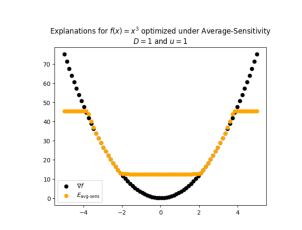
Optimizing Explanations: Nuances Matter When Evaluation Metrics Become Loss Functions
MOSS Workshop @ ICML 2025
Recent work has introduced a framework that allows users to directly optimize explanations for desired properties and their trade‑offs. While powerful in principle, this method repurposes evaluation metrics as loss functions. We study how different robustness metrics influence the outcome of explanation optimization, and find that the choice of metric can lead to highly divergent explanations, particularly in higher‑dimensional settings.